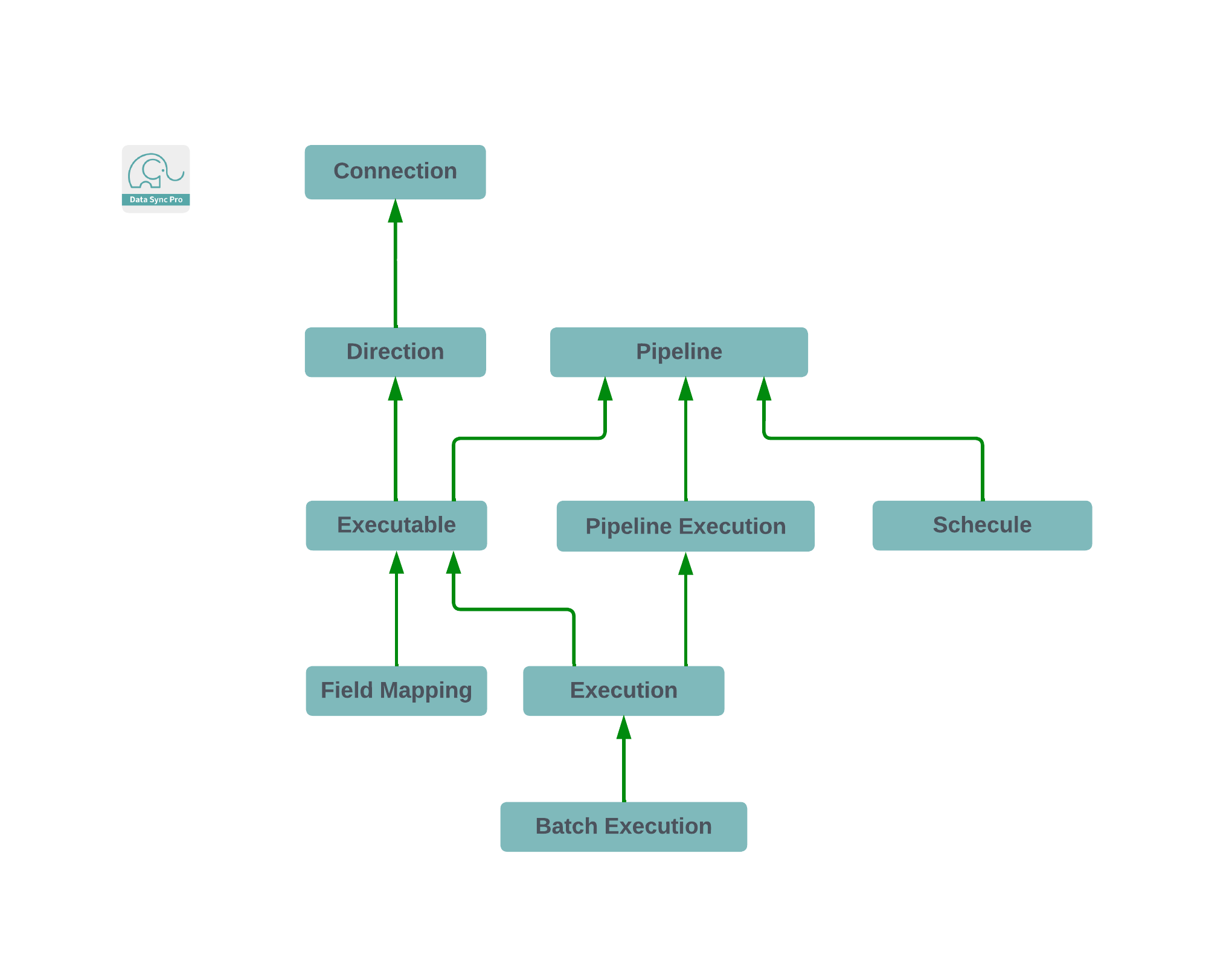
Directional Executable
A Directional Executable, integral to managed Salesforce data management, operates within a predefined Direction, establishing source and target connections for data synchronization. Upon creation, users select specific source and target objects, setting the stage for a wide range of Data Manipulation Language (DML) operations—insert, update, upsert, delete, undelete, and merge—toward the target object. Designed for versatility, this Executable functions as a batch job, adept at fetching data from the source, conducting matching and transformation processes, and executing actions on the target object, with the capability to run both on-demand and as scheduled, asynchronous batch jobs.
Designed for sophisticated data flow operations, Directional Executables excel when used in scenarios requiring data synchronization within a single Salesforce org. This capability is particularly noteworthy, as it positions Directional Executables not just for cross-org data transfers but as powerful tools for internal data management and optimization. When configured for intra-org operations, they facilitate comprehensive data tasks, including but not limited to, data cleansing, deduplication, and the enrichment of existing records. This use case underscores their utility in enhancing data quality and integrity without the necessity for external data movement, making them invaluable for organizations aiming to maintain a high standard of data within their Salesforce environment. By leveraging these Executables as batch jobs, businesses can automate complex data transformation and integration tasks, streamlining their internal processes and significantly reducing manual effort.
Incorporating a dynamic Q (query builder) component, the Executable enhances user interaction by facilitating the construction of SOQL queries for data retrieval, directly through a user-friendly interface. This allows for selective record execution based on predetermined transformations and actions, offering synchronous operations. The Q component, notable for features like inline and mass editing, downloading, and sorting, integrates smoothly into the Salesforce Lightning Experience via the Lightning App Builder.
Furthermore, when utilized within the current org as the source connection, the Directional Executable transcends its primary function, acting as a streamlined rules engine for trigger automations. By simplifying and bulkifying complex transformations and actions into user-configurable formulas, it presents a potent alternative to traditional triggers or flows, minimizing the need for extensive coding. Additionally, its adaptability extends to quick actions, enabling users to perform predefined operations with the simple click of a button, further demonstrating its utility and efficiency within the Salesforce platform.
Standalone Directional Executable
A Standalone Directional Executable operates independently, not linked to any Pipeline. This sub-type is designed for specific, isolated data management tasks that require direct and straightforward execution of data retrieval, transformation, and action processes between source and target connections. Ideal for singular, one-off tasks or when a task does not need to be part of a larger, sequential operation, Standalone Executables offer simplicity and direct control. They are particularly useful for simpler data synchronization needs where the sequence of operations or dependencies on other tasks is not a concern.
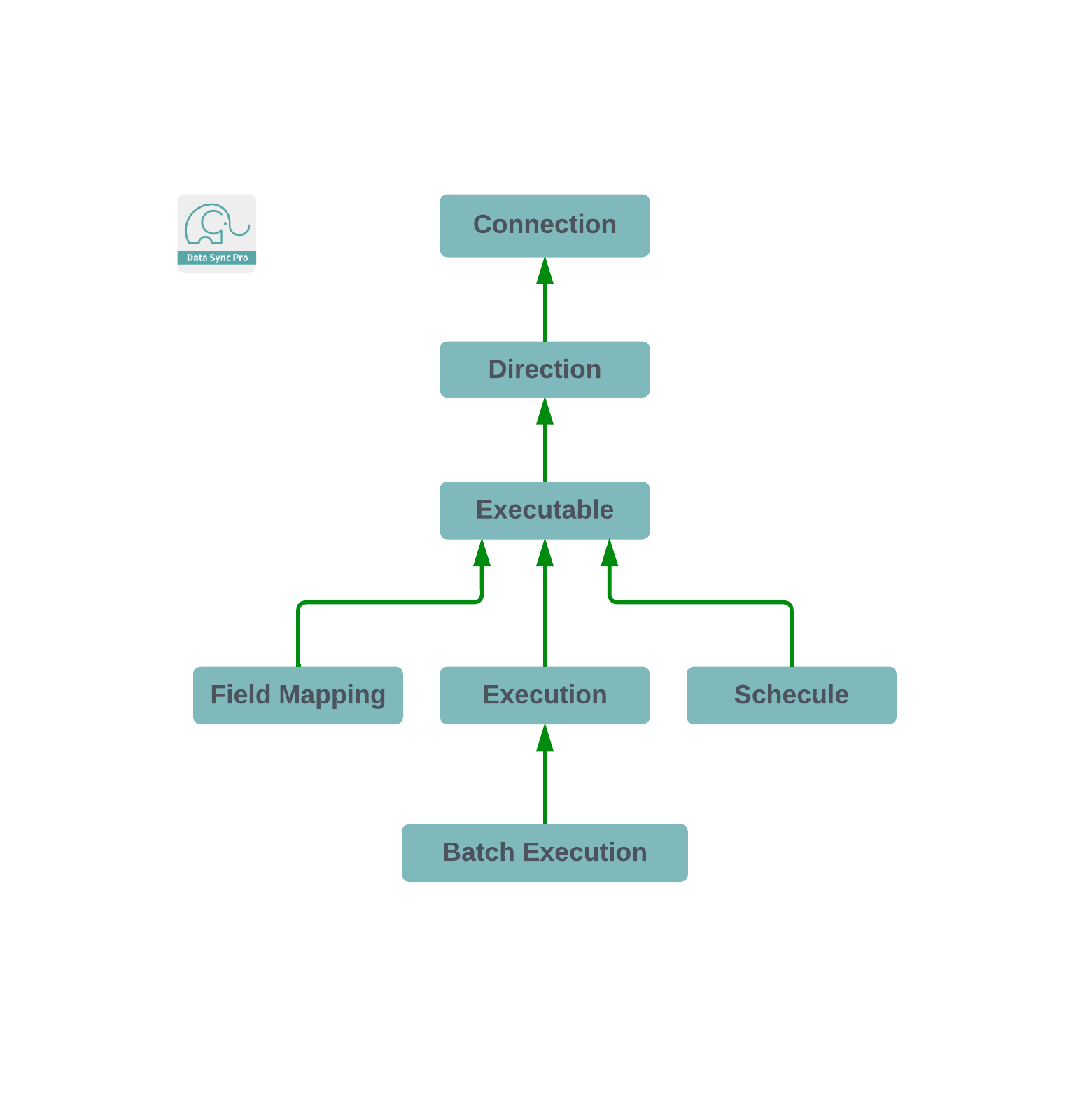
Pipeline Directional Executable
A Pipeline Directional Executable, in contrast, is part of a larger structured sequence within a Pipeline, allowing multiple Executables to be organized and executed in a specific order, denoted by a Sequence Number (Seq No). This sub-type facilitates complex data management scenarios where tasks must be performed in a precise sequence to achieve desired outcomes, such as cascading data updates or sequential data processing across different systems. By associating Executables with a Pipeline, users can architect sophisticated data flows that handle intricate transformations and actions, ensuring that each step is executed in the correct order for optimal data integrity and synchronization.
Pipeline Executables have the versatility to function just as effectively as Standalone Executables when operated individually. However, their true potential is unleashed within a Pipeline context, where they are executed in a sequential manner. This sequential execution is crucial for managing data dependencies accurately, ensuring that each step in the process is completed in the correct order before the next one begins. Essentially, when Pipeline Executables are run from a Pipeline, Salesforce's batch job chaining mechanism is utilized. This approach allows for the careful coordination of data processing tasks, maintaining the integrity and flow of data across multiple operations. By leveraging batch job chaining, Pipeline Executables provide a robust solution for complex data synchronization tasks, ensuring seamless and efficient data management within Salesforce.